Сигнал (от лат. signum “знак”, возможно, родств. лат. seco “секу”, т.е. букв. “засечка”) — изменение некоторой (физической) величины или набора величин, формируемое передатчикомtransmitter и воспринимаемое приёмникомreceiver. Сигнал — физическое представление данных, носитель информации.
Сообщение — логически целостная ограниченная во времени единица передачи.
Аналоговый сигналanalog signal — сигнал общего вида. Аналоговый сигнал невозможно передать абсолютно точно: среда передачи и само устройство передатчика и приёмника неизбежно вносят в сигнал искажения (шумы).
Аналоговый сигнал
Если имеют значение только замеры сигнала в фиксированные моменты времени (дискретное время), то говорят о дискретном сигнале. В случае равноотстоящих замеров можно говорить о частоте дискретизации — сколько замеров выполняется за единицу времени.
Дискретный сигнал
Если различимые уровни сигнала отделены друг от друга конечными промежутками, то сигнал называют квантованным. Общее количество допустимых и различимых уровней или шаг между уровнями называют разрешениемresolution.
Квантованный сигнал
Цифровой сигналdigital signal — дискретный квантованный сигнал.
Цифровой сигнал
Сообщения, передаваемые посредством цифровых сигналов (цифровые сообщения), можно представить в виде конечных строк, состоящих из символов конечного алфавита (соответствующих допустимым уровням сигнала). Таким образом, множество всех сообщений счётно, а множество сообщений, не превосходящих определённую длину (укладывающихся при передаче в определённое время), конечно. Поэтому при надлежащей работе оборудования возможна точная передача (“копирование”) цифровых сообщений. (Под возможностью понимается теоретическая способность сделать вероятность возникновения ошибок при передаче сколь угодно малой.) Среда и физический принцип передачи при этом могут меняться. Конкретный сигнал является физическим представлением сообщения.
Формирование передатчиком сообщения для передачи с помощью цифрового сигнала называется кодированием. Восприятие приёмником сообщения, переданного посредством цифрого сигнала, называется декодированием. Код — способ (формат) представления передаваемых данных.
Формирование цифрового сигнала для передачи через среду на основе сообщения называется манипуляциейkeying или цифровой модуляциейdigital modulation. Процесс формирования сообщения (внутреннего цифрового сигнала) на основе принимаемого сигнала называется демодуляцией. Соответственно, устройство, способное формировать и распознавать цифровой сигнал, может называться модулятором-демодулятором или сокращённо модемом.
Любую конечную строку, составленную из знаков конечного алфавита, можно трактовать как запись натурального числа, взяв в качестве цифр буквы этого алфавита. Одно и то же число можно записать разными цифрами (в разных системах счисления), что позволяет измерять объём произвольного цифрового сообщения не в знаках алфавита, из которых оно составлено, а в стандартизованных единицах. Чаще всего для этого используются двоичные цифры — биты. Так, если исходное сообщение составлено из n знаков алфавита размера r, то для его записи достаточно ⌈n log2r⌉ двоичных разрядов (бит). Таким образом, объём цифровых сообщений можно измерять в битах.
Автоматы
Система (через лат. systema от др.-греч. σύστημα “составленное (вместе)”) — организованная совокупность объектов (называемых элементами, компонентами или звеньями системы), находящихся во взаимосвязи друг с другом. Для описания системы необходимо описать каждый её элемент и все связи между элементами.
Чёрный ящикblack box — описание некоторого элемента системы только на основе её поведения, т. е. соответствия выходов заданным входам, без рассмотрения внутреннего устройства. Применяется в тех случаях, когда внутреннее устройство неизвестно или не важно.
Белый ящикwhite box — модель некоторой системы или элемента системы (чёрного ящика). Внутреннее устройство белого ящика известно (задано).
Чёрный и белый ящики
Обратная связьfeedback — зависимость входов элемента системы от его выходов. Обратная связь является одним из основных принципов управления. Наличие обратной связи позволяет системе реагировать на осуществляющееся в процессе развитие ситуации.
Обратная связь противопоставляется программному принципу управленияopen-loop control, который заключается в выполнении системой заранее заданной последовательности действий (“программы”), генерации заранее заложенных сигналов. Не следует путать этот термин с понятием компьютерной программы, так как реальные компьютерные программы допускают и, как правило, в той или иной мере реализуют принцип управления по обратной связи.
Классическое управление по обратной связи
Применительно к элементам, обменивающимся аналоговыми сигналами, используют термины отрицательная обратная связь и положительная обратная связь, подразумевая, что рост некоторого выходного сигнала вызывает изменение входного сигнала, вызывающее, соответственно, ослабление или дальнейшее усиление этого выходного сигнала. Типичным примером устройства, стабилизирующего систему с помощью введения отрицательной обратной связи, является центробежный регулятор.
Однако не всегда возможно надёжно стабилизировать систему простой обратной связью: например, из-за задержки между изменением входа и реакцией на него, которая существует в реальных системах, может возникнуть колебательный режим с достаточно большой для разрушения системы амплитудой.
Упреждающее управлениеfeedforward control (прогнозирование) — корректирование входов системы не на основе выходов, а на основе внутренней модели, реализованной в регуляторе. Позволяет вносить поправки до того, как появятся нарушения, которые надо исправлять (как может быть в случае классической обратной связи).
Упреждающее управление без обратной связи
Упреждающее управление можно комбинировать с обратной связью, позволяющей вносить корректировки в модель системы, используемой регулятором.
Упреждающее управление с обратной связью
На иллюстрации ниже изображена система из двух элементов: рабочего звенаB (объекта управления) и управляющего звенаA. На вход системы подаётся сигнал a(t), на основе которого (а также на основе своего состояния) рабочее звено формирует сигнал x(t) (наблюдение), подаваемый на вход управляющего звена, которое, в свою очередь, вырабатывает управляющий сигнал y(t). Итоговый выход системы показан как сигнал b(t). Наличие циклической связи B → A → B является признаком существования обратной связи.
Двухзвенная система с управлением по обратной связи
Автомат — звено, обладающее явным состоянием (памятью). Работа (динамика) автомата может описываться парой функций f и g (t — переменная времени, x(t) — входной сигнал, y(t) — выходной сигнал, z(t) — состояние автомата):
y(t) = f(t, x(t), H[t0, t, z]),
z(t) = g(t, x(t), H[t0, t, z]).
Здесь H — оператор истории (временной момент начала работы обозначен как t0). В общем случае, автомат может помнить всю историю изменения своего состояния. В простейшем случае можно положить H[t0, t, z] ≡ z(t), тогда поведение автомата не зависит от ранее пройденных им состояний, а зависит только от текущего состояния.
Автомат общего вида
Если все сигналы цифровые (цифровой автомат), то непрерывное время t заменяется последовательностью шагов, что обозначается индексом: например, x(ti) = xi, i ∈ ℕ, при этом каждое значение каждого сигнала принимает значение из соответствующего конечного множества: ∀i ∈ ℕ xi ∈ X, yi ∈ Y, zi ∈ Z. Форма оператора истории H[t0, t, z] приобретает вид H[i, z]. В простейшем случае имеем H[i, z] ≡ zi и динамику вида:
yi = f(xi, zi),
zi+1 = g(xi, zi).
Для полного определения динамики автомата должно быть также задано начальное состояние z0. Далее под словом “автомат” понимается цифровой автомат.
Так как множество возможных состояний Z конечно, такой автомат (не запоминающий историю прошлых состояний) называется конечнымfinite state machine, finite automaton (КА, FA, FSM).
В случае конечного автомата множества X и Z конечные (их элементы можно пронумеровать и затем использовать номера вместо самих значений), поэтому можно заменить вычисление функций f и g выборкой из двух заранее составленных таблиц F и G, т. е. вместо выполнения во время работы автомата вычислений просто извлекать требуемые значения из некоторого запоминающего устройства. Ниже представлена схема возможной реализации подобного автомата.
Схема реализации конечного автомата на основе таблиц
Каждый шаг работы автомата состоит из двух тактов: (чёрные стрелки) ввод-вывод и загрузка состояния, полученного на предыдущем шаге, (красные стрелки) выборка из таблиц выходного значения и значения следующего состояния. Пунктирные стрелки обозначают передачу адреса в банки ПЗУ, реализующие таблицы F и G (адрес — конкатенация значений регистров входа и состояния). Сплошные стрелки обозначают передачу (чтение-запись) данных. В начале работы в регистр “следующее состояние” должно быть помещено начальное состояние z0 (точнее, его номер в нумерации Z).
Преимуществом подобной схемы организации автомата является возможность изменять его поведение уже после изготовления устройства. Для этого достаточно поменять содержимое таблиц (если использовалось ПЗУ с возможностью перезаписи, например, Flash-память). Недостатком — большой требуемый объём памяти.
Описание работы конечных автоматов обычно выполняют в виде набора правил. Т. е. часть значений F и G даётся в виде перечисления (x, z) → (f(x, z), g(x, z)). Если имеет значение только попадание автомата в определённое состояние (распознавание определённой входной последовательности), и выход автомата не используется, то выход не пишут, и тогда правая часть правила содержит только следующее состояние автомата. Если случается комбинация входа x и состояния z, для которой не задано подходящего правила перехода, то считается, что автомат застопориваетсяgets stuck и прекращает работу (можно считать это особым состоянием автомата).
Для краткости записи правила нередко обобщаются на классы правил: например, (цифра, состояние) → (новое состояние), в том числе параметризованные — (букваa, состояние) → (“L” a, новое состояние). В последнем правиле подразумевается вывод конкатенации символа “L” и символа считанной буквы a, которая может быть любой (a — имя переменной). Конечный автомат может отправлять на выход строки вместо отдельных символов, так как их (разных строк) всё равно конечное число (не превосходящее количество элементов таблиц F и G — элементарных правил).
Краткая запись правил часто может быть напрямую переведена на язык программирования, что даёт достаточно компактное представление конечного автомата в программе, не требующее значительных затрат памяти на прямое формирование таблиц.
Конечные автоматы широко применяются в управлении цифровыми системами. В частности, процессоры современных компьютеров содержат множество конечных автоматов, с помощью которых выполняется управление исполнительными устройствами процессора.
Так как объём памяти реального цифрового компьютера ограничен, то его также можно считать конечным автоматом с теоретической точки зрения. Однако, количество возможных состояний даже у компьютера с очень небольшим объёмом памяти столь велико (например, у микроконтроллера семейства Intel 8051 может быть 256 байт ОЗУ, что соответствует 22048 ≈ 3·10616 различных состояний), что с практической точки зрения продуктивнее модели, предусматривающие неограниченно большое количество состояний.
Модели вычислителей
Вычислимые функции
Процесс работы автомата можно рассматривать как потенциально бесконечную последовательность шагов, при этом описание полного состояния автомата (даже если он не является конечным и обладает неограниченной памятью — см. ниже) на каждом шаге конечно. Часто удобно считать, что получив некоторый “ввод”, автомат должен, проделав некоторое количество шагов, сформировать некоторый “вывод” (результат работы) и остановитьсяto halt. Факт останова можно определять как принадлежность полного состояния некоторому множеству (может быть просто определён специальный элемент множества Z со смыслом “останов”). Застопоривание автомата считается частным случаем останова.
В ряде случаев, однако, может получаться так, что хотя состояния останова и определены, но для некоторых вводов автомат никогда не приходит в состояния останова. Такая ситуация называется зависаниемhanging.
Вычислимой функциейcomputable function будем называть функцию, для вычисления которой может быть сконструирован некоторый автомат, который для любого аргумента из области определения функции вычисляет значение этой функции за конечное число шагов, после чего останавливается (т.е. потенциально осуществим вычислитель для данной функции).
Так как аргумент и результат функции должны иметь конечное копируемое представление, множество всех вычислимых функций можно считать подмножеством функций вида ℕ → ℕ.
Теорема (о существовании невычислимых функций). Множество вычислимых функций вида f : ℕ → ℕ является строгим подмножеством всех функций вида ℕ → ℕ.
Доказательство
Для доказательства воспользуемся построением, известным как “диагональный элемент Кантора”. Рассмотрим строгое подмножество всех натуральнозначных функций натуральных чисел: множество предикатов натуральных чисел ℕ → {0, 1}.
Предположим, что это множество счётно, т.е. существует взаимно-однозначное отображение этого множества во множество ℕ (нумерация). Тогда для любого N ∈ ℕ можно выписать значения первых N функций в этой нумерации на произвольном количестве натуральных чисел-аргументов. Возмём N первых натуральных чисел в качестве аргументов. Таким образом, получим N×N (0, 1)-матрицу. Что-то вроде
Пример вычисления диагонального элемента
№f \ арг.
0
1
2
3
4
5
0
0
0
1
1
0
1
1
1
0
0
0
1
1
2
0
1
1
1
0
0
3
0
0
0
0
0
1
4
1
1
0
0
0
0
5
0
1
0
0
0
1
диагон.
0
0
1
0
0
1
¬диагон.
1
1
0
1
1
0
Какую бы нумерацию и какое бы N мы не выбрали, мы всегда можем построить новую функцию, которая в эту нумерацию не попадает, взяв диагональные элементы матрицы и выполнив инверсию (0 заменяем на 1 и наоборот). Новая функция не равна ни одной функции из нумерации.
Таким образом, множество всех предикатов натуральных чисел несчётно. В то же время, множество всех вычислимых функций счётно, так как счётно множество всех автоматов, имеющих конечное описание. Следовательно, среди предикатов натуральных чисел (не говоря уже о более широком классе ℕ → ℕ) есть невычислимые функции. □
Следствие (невычислимость действительных чисел). Не для каждого действительного числа можно сконструировать автомат, перечисляющий цифры этого числа.
Счётное множество называется вычислимым или разрешимымdecidable, если его индикатор — вычислимая функция. Дополнение вычислимого множества также вычислимо.
Счётное множество называется полуразрешимымsemidecidable, если существует автомат, который для каждого элемента множества корректно вычисляет индикатор (возвращает 1), а для значений, не принадлежащих множеству либо корректно вычисляет индикатор (возвращает 0), либо зависает. Дополнение полуразрешимого множества не является полуразрешимым, а значит, и вычислимым множеством.
Вычислительные способности автоматов (“мощность”) можно сравнивать. Если автомат (или автоматы одного семейства) может вычислять все те же функции, что и другой автомат (или автоматы другого семейства), то этот автомат не менее мощный, чем другой. Автоматы имеют равную мощность, если множества функций, которые они могут вычислять совпадают.
Слова “те же” и “совпадают” выделены курсивом, потому что разные автоматы могут использовать разное кодирование исходных данных и результата, при этом механизм кодирования не включается в рассмотрение как часть автомата, лишь предполагается, что он относительно прост (иначе может оказаться, что функции вычисляются при “кодировании-декодировании” и все автоматы эквивалентны друг другу, что бессмысленно).
Сравнение по мощности производится попыткой построить моделирование одним автоматом работы другого автомата. Если автомат способен моделировать поведение другого автомата, то он способен вычислять те же функции и, таким образом, не менее мощный.
На схеме показана замкнутая система, так как для определения абстрактного вычислителя вопросы взаимодействия с внешним миром не являются первостепенными: будем считать, что взаимодействие может осуществляться через запоминающее устройство.
Машина Тьюринга
Пусть запоминающее устройство использует ленту неограниченной в обе стороны длины. По ленте перемещается головка, способная считывать и записывать символы. Алфавит ленты состоит из элементов множества X, при этом один из них должен соответствовать “пустой ячейке”. В начале работы все ячейки ленты кроме конечного числа ячеек, содержащих ввод, пусты (содержат специальный символ “пустая ячейка”).
Работа запоминающего устройства на каждый шаг автомата состоит из трёх стадий:
Чтение символа из текущей ячейки и отправка его автомату в качестве входа.
Запись выходного символа в текущую ячейку.
Перемещение головки на шаг влево или на шаг вправо.
Лента — запоминающее устройство машины Тьюринга
Чтобы реализовать пп.2–3, следует положить Y = X × {←, →}. Таким образом, автомат на каждом шаге должен возвращать пару “символ для записи”, “команда перемещения”. Для удобства нередко расширяют набор команд ещё двумя: “стоять на месте” (не перемещать головку на этом шаге) и “остановиться” (прекратить работу — застопорить автомат).
Такая машина называется машиной ТьюрингаTuring machine (МТ) и была описана Аланом Тьюрингом в 1935г. как математическое определение алгоритма (каждому алгоритму соответствует своя машина Тьюринга). Фактически она возникла как абстрактное описание действий человека с формулами на бумаге: бумагу заменили на одномерную ленту, а человека, выполняющего действия по строго заданным правилам, на конечный автомат.
Очевидно, что машина Тьюринга способна моделировать работу конечного автомата: для этого достаточно двигаться только в одну сторону (всегда влево или всегда вправо). Так как размер ленты не ограничен, машина Тьюринга способна вычислять функции, недоступные для конечных автоматов, например, складывать числа произвольной величины. Поэтому МТ является строго более мощным вычислителем, чем КА. В общем-то то же самое можно сказать о любом вычислителе, представляющем собой дополнение конечного автомата памятью неограниченного объёма. Но можно ли построить вычислитель более мощный, нежели машина Тьюринга?
Универсальной машиной Тьюринга (УМТ) называют такую МТ, которая принимает на вход некоторое описание любой другой МТ и закодированный ввод для неё и способна моделировать работу этой другой МТ (количество требуемых шагов при этом может значительно возрастать), получая в закодированной форме вывод моделируемой машины. Кодирование и декодирование являются необходимым элементом, потому что алфавит (множество X) УМТ зафиксирован, в то время как моделируемая МТ может пользоваться другим алфавитом, в том числе, большего размера.
Существование УМТ было доказано ещё Тьюрингом. Этот факт влечёт то следствие, что аналогичные универсальные машины есть в любых семействах автоматов, эквивалентных по вычислительным способностям семейству МТ. Теоретический интерес представляет вопрос построения минимальных по размеру описания универсальных машин. Широко известным примером “малой” УМТ является “(2, 3)-машина”, предложенная С. Вольфрамом. Она может находиться всего лишь в двух состояниях и использует алфавит из трёх символов.
Автомат, способный моделировать поведение УМТ (то же самое, что и любой МТ), называют полным по ТьюрингуTuring-complete.
Многоленточная машина Тьюринга
Многоленточной машиной Тьюрингаmultitape Turing machine называют расширение МТ, полученное засчёт механического дублирования памяти. Т.е. потенциально бесконечных лент и головок становится несколько (но фиксированное число) и входной сигнал автомата формируется как кортеж символов в текущих позициях на всех лентах, а выходной сигнал содержит кортеж символов на запись на всех лентах и вектор действий для всех головок.
Оказывается, для любой многоленточной МТ можно составить моделирующую её одноленточную МТ. Для этого можно применить следующий приём: на одной ленте выписываются подряд пары: (символ на очередной моделируемой ленте, маркер положения головки на соответствующей ленте в этой позиции).
Пример (трёхленточная МТ, положение головок указано полужирным шрифтом):
…123… …abc… …φχψ…
Представление этих участков трёх лент на одной общей ленте (в качестве маркера отсутствия головки используется знак “–”, присутствия — “+”):
…1–a+φ–2–b–χ+3+c–ψ–…
Таким образом, многоленточная МТ эквивалентна одноленточной МТ (но может решать какие-то задачи за меньшее число шагов).
Двумерная машина Тьюринга
Представим, что вместо одномерной ленты головка машины Тьюринга может перемещаться по неограниченному во всех направлениях двумерному полю ячеек.
Пример состояния памяти двумерной машины Тьюринга
Такая машина Тьюринга называется двумерной машиной Тьюринга. Аналогично можно расширить МТ до использования памяти произвольной размерности.
Оказывается, двумерную МТ можно смоделировать на двухленточной МТ: при этом одна лента содержит все задействованные строки, концы которых помечены специальными маркерами, а вторая — вспомогательную информацию о положении головки на сетке. В таком случае при выходе за пределы строк их приходится расширять и перемещать значительную часть содержимого ленты, да и при переходе вверх-вниз по уже задействованным ранее ячейкам головке моделирующей машины придётся пробежать значительное расстояние, поэтому такое моделирование требует от моделирующей машины совершать намного больше шагов, чем совершала бы моделируемая машина. Тем не менее, множество вычислимых функций, доступных двумерной МТ, то же самое, что и для обычной МТ. Это же справедливо и для МТ любой фиксированной размерности.
Автомат с последовательной памятью
Автомат с последовательной памятьюqueue automaton (АПП) в качестве памяти использует очередь символов. При чтении из очереди извлекается самый левый символ (записанный первым из имеющихся). При записи в очередь справа дописывается некоторая последовательность символов (всего таких последовательностей конечное число — они формируют множество выходов Y).
Последовательная память — очередь символов
Нетрудно показать, что для любого автомата с последовательной памятью можно построить моделирующую его машину Тьюринга. Что более интересно, так это тот факт, что всегда можно сделать и обратное — для заданной МТ построить АПП. Таким образом, АПП и МТ эквивалентны по вычислительным способностям.
Клеточные автоматы
Клеточным автоматомcellular automaton называют структуру, составленную из синхронизированных (выполняют шаги одновременно) соединённых автоматов (обычно конечных), где на вход каждого из них поступает набор выходов некоторого набора соседних автоматов (“ячеек” cells), составляющих “окрестность” neighborhood. Соответственно, выход каждой ячейки дублируется для всех ячеек из её окрестности. Обычно предполагается, что структура автомата регулярна и количество ячеек велико (или даже бесконечно).
Клеточный автомат на основе прямоугольной двумерной сетки
По количеству ячеек можно выделить следующие случаи:
Количество ячеек ограничено. Если ячейки — конечные автоматы, то и клеточный автомат в целом является конечным, хотя количество различных его состояний может быть очень и очень велико. Топология таких автоматов может строиться на основе ограниченной поверхности (есть граничные ячейки с уменьшенной окрестностью: например, матрица n×m ячеек, у угловых ячеек всего по двое соседей) или замкнутой поверхности (популярен вариант “тор” или “решётка” grid благодаря простоте реализации и некоторым свойствам).
Количество ячеек не ограничено, но на каждом шаге “активно” только конечное число ячеек. Считаем, что на старте бесконечное множество ячеек находится в некотором нулевом состоянии, из которого они могут выйти только получив вход от ячейки, находящейся в ненулевом состоянии. В некотором смысле данная модель похожа на многомерную МТ, но количество задействованных ячеек может расти с каждым шагом в геометрической прогрессии.
Количество ячеек бесконечно, и все они могут выполнять полезную работу. Это истинно бесконечный автомат (описание его состояния на одном шаге может быть бесконечно), являющийся чисто абстрактной моделью.
Машина Тьюринга может моделировать клеточный автомат, если она может моделировать поведение каждой ячейки, и количество активных ячеек конечно на каждом шаге автомата. Естественно, МТ не может моделировать истинно бесконечный клеточный автомат. Однако и создать такое физическое устройство не представляется возможным.
В свою очередь, неограниченные клеточные автоматы, ячейки которых являются лишь конечными автоматами, часто способны моделировать произвольную МТ. Один из простейших одномерных клеточных автоматов такого рода известен под названием “Правило 110”. Самым известным клеточным автоматом является двумерный автомат “Игра “Жизнь”. Этот автомат также способен моделировать произвольную МТ. Они оба используют ячейки, способные находиться всего лишь в двух различных состояниях.
Пример работы автомата “Жизнь” (Wikipedia)
Клеточные автоматы нередко используют для моделирования физических процессов или каких-то сетевых или пространственных структур. Например, автомат Wireworld был придуман как средство моделирования логических схем.
Пример работы автомата Wireworld (Wikipedia)
Проблема останова
При исследовании поведения конечных автоматов можно получить достаточно много качественных результатов, например, за конечное число шагов можно узнать, достижимо ли одно состояние из другого за произвольное число шагов при входах из заданного подмножества X. Вопрос, придёт ли конечный автомат на заданном вводе в некоторое состояние, легко решается прямым моделированием (подразумевается ввод конечной длины).
А что же будет, если конечный автомат заменить на машину Тьюринга (или любой эквивалентный класс автоматов)? Оказывается, что вопрос, “придёт ли заданная МТ на заданном конечном вводе в некоторое состояние” оказывается в общем случае не разрешим. Частным случаем данной задачи, который и дал вынесенное в заголовок название “проблема останова”, является вопрос о существовании алгоритма (в форме машины Тьюринга, решающей этот вопрос за конечное число шагов) для того, чтобы проверить, остановится (придёт в состояние останова) заданная МТ на заданном вводе или зависнет.
Показать несуществование такого алгоритма в общем случае можно с помощью доказательства методом “от противного”, которое можно описать в упрощённом виде следующим образом.
В качестве абстракции автомата будем говорить о “программах”. Каждая программа является конечной последовательностью символов и кодирует конкретный автомат некоторого достаточно широкого семейства. Произвольная программа получает ввод и формирует вывод, которые также представлены в виде конечных строк из тех же символов. Поэтому программы удобно в абстрактной форме представлять в виде функций, отображающих строку в строку.
Итак, пусть есть функция остановится, ввод которой должен состоять из программы и ввода этой программы, а вывод — истина или ложь. Конкатенацию строк (с добавлением маркеров, если нужно) будем обозначать перечислением строк через запятую: остановится(программа, ввод) → {0, 1}.
Опишем новую функцию проверка, принимающую на вход произвольную программу:
парадокс(программа) = если остановится(программа, программа), то войти в вечный цикл, иначе останов.
Теперь вопрос, что возвратит вызов остановится(парадокс, парадокс)? Если истину, то парадокс должна войти в вечный цикл, то есть зависнуть, значит, проверка на останов должна вернуть ложь. Но если она вернёт ложь, то парадокс должна остановиться, а значит, проверка на останов должна вернуть истину. Получаем противоречие, из которого следует, что не существует такой функции остановится. □
Что интересно, так это то, что данный факт на самом деле не привязан к машинам Тьюринга. Если представить, что существует более мощный класс автоматов, то в этом классе можно получить тот же результат: среди них не будет существовать автомата, способного в общем случае решить вопрос о попадании в заданное состояние на заданном вводе произвольного заданного автомата из того же класса за конечное число шагов.
Функция остановится является примером невычислимой функции.
Множество машин Тьюринга, которые останавливаются на всех вводах, является счётным и полуразрешимым.
Пока что все предложенные конструктивные механизмы, позволяющие действительно моделировать вычисления (и построить физические устройства, выполняющие вычисления по такой схеме), не превосходят по вычислительным способностям машины Тьюринга. Все самые “мощные” подобные механизмы являются Тьюринг-полными и эквивалентными по вычислительным возможностям классу машин Тьюринга.
Этот факт дал основу для гипотезы, известной как тезис Тьюринга-Чёрча, который гласит, что [оперирующие цифровыми сигналами] вычислители, способные вычислять функции, не вычислимые в классе машин Тьюринга, физически не реализуемы.
Такие гипотетические вычислители, называют гипервычислителямиhypercomputers. Данное понятие можно использовать в абстрактных математических построениях. Примером гипервычислителя является регистровая машина, реализующая арифметику действительных чисел (“RealRAM”).
Регистровые машины
Как это нередко бывает, практика идёт своим путём, отличным от имеющихся теоретических построений, и чтобы анализировать достигнутые в ходе развития реальной техники результаты, приходится строить новые теоретические модели. Нечто подобное произошло с компьютерами. Реальные компьютеры оказались не слишком похожи на машины Тьюринга, хотя общая схема всё ещё напоминает модель “автомат с памятью”: есть “процессор”, который выполняет некоторые действия и “память”, которая хранит данные. Особенностью реальных машин оказалось то, что их оперативная память допускает произвольную адресацию. Можно сказать, что это таблица пронумерованных ячеек со значениями, и по номеру ячейки (её “адресу”) можно сразу получить (“прочитать”) её значение или записать туда новое значение. В данном контексте такие ячейки памяти называются регистрами. Обычно предполагается, что регистры могут хранить произвольное натуральное число (в отличие от машины Тьюринга, ячейки ленты которой могут принимать значения лишь из конечного множества).
Схема регистровой машины
На иллюстрации приведена условная схема “регистровой машины”, которая состоит из трёх частей: процессора, выполняющего операции над натуральными числами, программы (ПЗУ), которая представляет собой последовательность пронумерованных инструкций (о них ниже) и памяти (ОЗУ), состоящей из пронумерованных регистров.
В составе процессора выделены два особых регистра, не входящих в состав ОЗУ: счётчик программыprogram counter, PC и селектор регистраregister selector, RS. На каждом шаге процессор считывает из программы инструкцию по номеру, хранящемуся в регистре PC, затем увеличивает этот регистр на единицу (переход к следующей инструкции). Номер очередного регистра, к которому надо обратиться в процессе работы, помещается в регистр RS. Таким образом, регистры PC и RS хранят адреса текущих элементов таблиц “программа” и “память” соответственно, а данные ячеек таблиц по указанным адресам поступают в процессор по шинам команд и данных соответственно.
Без ограничения общности можно считать, что множество значений регистра PC является конечным, так как программа имеет конечное количество инструкций, а при выходе за пределы программы машина останавливается. Поэтому значение PC может считаться состоянием конечного автомата, управляющего машиной, в то время как подключенная к нему состоящая из регистров память имеет неограниченные размеры.
Английским эквивалентом русского термина шина является слово bus. Это же слово переводится как “автобус”. В свою очередь, слово автобус происходит от комбинации слов автомобиль и омнибус, а bus — попросту сокращённое omnibus. Откуда же взялось omnibus? Данное слово является латинским местоимением omnis (“все”) в дательном падеже, т.е. букв. “всем”. Такое название подчёркивало общедоступность этого первого вида городского общественного транспорта. Интересно, что данный термин также был применён и в электронике: первоначально “шиной” (“bus”) называли набор контактных линий, соединяющий физически сразу несколько устройств, так что передача каждого устройства, подключенного к шине, видна всем остальным.
Русское слово шина происходит от немецкого Schiene “рельс”. Значение “автомобильная шина”, вероятно, этимологически связано с использованием слова “шина” в значение “полоз” ещё в XVIII веке (по данным словаря Фасмера).
Машина-счётчик
Простейшим видом регистровой машины является машина-счётчикcounter machine. Её особенностями являются минимальный набор команд (достаточный для выполнения арифметических действий) и наличие заранее фиксированного набора регистров (конечное число), к которым можно обращаться по номеру, указанному в команде.
Машина-счётчик является абстракцией, созданной для исследования возможностей самых простых вариантов регистровых машин. Необходимо отметить, что хотя регистров конечное число, объём доступной памяти формально не ограничен, так как каждый регистр может хранить произвольное натуральное число. Часто предполагается, что перед началом выполнения программы в определённые регистры уже записаны определённые числа, играющие роль ввода или вспомогательных констант, используемых в процессе работы программы (например, часто предполагается, что регистр 0 всегда равен 0).
В работах разных авторов используются разные конкретные наборы команд. Рассмотрим некоторые такие модели.
Модели
Модель 1
Три команды:
INC r: увеличить регистр за номером r на 1 (“инкремент”).
DEC r: уменьшить регистр за номером r на 1 (“декремент”). В случае, если r равен нулю, команда DEC r оставляет его неизменным.
JZ r, z: если регистр за номером r равен нулю, заменить значение PC на число z (условный переход).
Данная модель напоминает счёты: INC r означает “перекинуть костяшку на ряду r налево”, DEC r означает “перекинуть костяшку на ряду r направо”, JZ r, z означает “посмотреть, есть ли на ряду r костяшки слева, и если нет, перейти на инструкцию за номером z, иначе продолжить со следующей инструкции”.
Модель 2
Три команды:
CLR r: записать в регистр r нуль (“очистить его”).
INC r: увеличить регистр за номером r на 1 (“инкремент”).
JE p, q, z: если регистры p и q равны, заменить значение PC на число z (условный переход).
Одна команда с четырьмя параметрами: SUBNZ a, b, c, z (“вычесть и перейти, если не нуль”) — записать в регистр с номером a разность регистров с номерами b и c и перейти на инструкцию z, если значения регистров b и c различны. Так как набор возможных команд состоит всего лишь из одного элемента, можно записывать программу как последовательность четвёрок (a, b, c, z), последний элемент для краткости часто может опускаться, если он равен номеру следующей инструкции (т.е. всё действие команды сводится к вычитанию). Подобные модели объединяются под общим названием OISC (one instruction set computer — “компьютер с набором команд, состоящим из одной инструкции”).
При использовании данной модели желательно расширить множество возможных значений регистров до всех целых чисел. В этом случае достаточно легко “перевести”, например, команды модели 2 на язык модели 3:
CLR r = SUBNZ r, r, r: записать разность r с r в r и перейти к следующей инструкции.
JE p, q, z:
SUBNZ t0, p, q, Skip
SUBNZ t0, t1, t2, z
Skip: …
Здесь t0, t1 и t2 — вспомогательные регистры, причём требуется, чтобы значения регистров t1 и t2 всегда были разными, иными словами, вторая команда является реализацией безусловного перехода, а метка Skip устанавливается на команду, следующую за этими двумя.
INC r легко записать, если разрешается использовать произвольные целые числа:
SUBNZ r, r, n
Здесь регистр n является вспомогательным регистром, в котором хранится значение –1.
Модель 4
При желании использовать OISC, оперирующий только натуральными числами и способный моделировать, например, команды модели 1, можно использовать команду ACJE (add comparison, jump if equal — “добавить результат сравнения, перейти если равны”) с четырьмя аргументами:
ACJE a, b, c, z:
если значение регистра b меньше значения регистра c, то уменьшить a на единицу,
иначе если значение регистра b больше значения регистра c, то увеличить a на единицу,
иначе (т.е. когда значения регистров b и c равны) перейти на метку z.
Данная команда была специально придумана автором, чтобы через неё можно было легко воссоздать команды модели 1.
Упражнение. Запишите команды INC, DEC и JZ через ACJE.
Упражнение. Придумайте команду OISC, позволяющую удобно (без циклов) записать команды модели 2, оперируя при этом только натуральными числами.
Теорема. Модели 1–4 эквивалентны по вычислительным возможностям, т.е. для каждой программы, заданной на фиксированном наборе регистров одной из моделей, можно составить эквивалентную программу (возможно, использующую другой набор регистров — другое количество и другие начальные значения) в рамках любой другой модели.
Не будем рассматривать доказательство этой теоремы целиком. В качестве достаточно короткого примера рассмотрим лишь сведение модели 2 к модели 1. Для того, чтобы “переводить” программы, написанные для модели 1, в программы для модели 2, следует сформулировать схемы замены команд DEC и JZ на команды модели 2.
Доказательства тех или иных утверждений о программах для машин-счётчиков удобно проводить с помощью математической индукции. Конкретная модель задаёт набор аксиом, определяющих семантику каждой команды.
Пронумеруем шаги машины. Значение регистра (включая специальный регистр PC) на шаге i будем обозначать индексом, например, ri — значение регистра r на шаге i. Инструкцию с номером p будем обозначать I[p].
Общая аксиома для всех моделей:
Если команда не задействует регистр, то его значение на следующем шаге равно его значению на предыдущем шаге.
Аксиомы модели 1:
Пусть I[PCi] = INC r. Тогда PCi+1 = PCi + 1 и ri+1 = ri + 1.
Пусть I[PCi] = DEC r. Тогда PCi+1 = PCi + 1 и если ri > 0, то ri+1 = ri – 1, в противном случае ri+1 = 0.
Пусть I[PCi] = JZ r, z. Тогда ri+1 = ri, и если ri = 0, то PCi+1 = z, иначе PCi+1 = PCi + 1.
Аксиомы модели 2:
Пусть I[PCi] = CLR r. Тогда PCi+1 = PCi + 1 и ri+1 = 0.
Пусть I[PCi] = INC r. Тогда PCi+1 = PCi + 1 и ri+1 = ri + 1.
Пусть I[PCi] = JE p, q, z. Тогда pi+1 = pi, qi+1 = qi, и если pi = qi, то PCi+1 = z, иначе PCi+1 = PCi + 1.
Лемма 1. Пусть регистр 0 содержит значение 0, тогда команда JZ r, z эквивалентна следующему фрагменту (при подстановке выполняется замена r на номер конкретного регистра):
JE r, 0, z
Под эквивалентностью понимается выполнение соответствующей аксиомы другой модели, взятой как утверждение с подменой, впрочем, фрагментов вида PCi+1 = PCi + 1 на PCi+1 = PCi + m, где m > 0 — длина замещающего фрагмента. В случае леммы 1 m = 1, однако в леммах 2 и 3 это уже не так.
Доказательство. Подставляем p = r и q = 0, значение которого раскрываем как 0, в аксиому 2.3 и получаем аксиому 1.3 как следствие. □
Лемма 2. Пусть регистр 0 содержит значение 0. Тогда можно ввести псевдокоманду CPY a, b, выполняющую копирование значение регистра a в регистр b (предыдущее значение регистра b при этом теряется) в виде следующего фрагмента кода (при подстановке выполняется не только замена a и b на соответствующие номера, но и меток на настоящие номера инструкций — строчки ниже пронумерованы для удобства ссылок из доказательства):
CLR b
IncLoop: JE a, b, End
INC b
JE 0, 0, IncLoop
End: место для инструкции, следующей за CPY
Доказательство.
Случай “значение регистра a = 0”.
По аксиоме 2.1 новое значение регистра b = 0.
Значения a и b равны, по аксиоме 2.3 новое значение PC = End (5).
После CPY имеем значение b = значению a.
Случай “значение регистра a ≠ 0”.
Докажем, что если значение регистра b ≤ значению регистра a, то выполнение строк 2–4 “подтягивает” значение регистра b до значения регистра a (которые остаётся неизменным). Для этого воспользуемся методом математической индукции. Положим d = разности значений регистров a и b.
База индукции. Пусть d = 0.
Значения регистров a и b равны, по аксиоме 2.3 новое значение PC = End (5).
После CPY имеем значение b = значению a.
Шаг индукции. Предположим, что d = n > 0 и выполнение строк 2–4 изменяет регистр b таким образом, что он становится равным регистру a. Докажем, что то же самое свойство тогда выполняется и для d = n + 1.
Значения регистров a и b не равны, по аксиоме 2.3 новое значение PC = адресу следующей инструкции.
По аксиоме 2.2 новое значение b стало больше на единицу, а значит, теперь d = n.
Безусловный переход на 2, таким образом, строки 2–4 повторяются для случая d = n, что по предположению шага индукции даёт желаемый результат: после CPY имеем значение b = значению a.
□
Лемма 3. Пусть регистр 0 содержит значение 0 и регистры 1 и 2 играют вспомогательную роль (не используются для хранения данных или констант). Тогда команду DEC r можно представить в виде следующего фрагмента кода:
JE 0, r, End
CLR 1
CLR 2
IncLoop: INC 2
JE 2, r, Copy
INC 1
JE 0, 0, IncLoop
Copy: CPY 1, r
End: место для инструкции, следующей за DEC
Доказательство
Случай “значение регистра r = 0”.
По аксиоме 2.3 следующее значение PC = End (9), значение регистра r не меняется (“противный случай” в аксиоме 1.2).
После DEC r имеем r = 0.
Случай “значение регистра r ≠ 0”.
По аксиоме 2.3 переходим к следующей инструкции.
По аксиоме 2.1 значение регистра 1 становится 0.
По аксиоме 2.1 значение регистра 2 становится 0.
По аксиоме 2.2 значение регистра 2 становится 1.
Выход из цикла 4–7 возможен только на строку 8 (по переходу на строке 5).
База индукции. В качестве переменной индукции будем рассматривать разность d между значениями регистров r и 2 в момент первого выполнения строки 5. Пусть d = 0 (т.е. регистр r содержал 1), тогда по аксиоме 2.3 переходим на строку 8 и записываем в регистр r значение 0 (лемма 2), т.е. уменьшено на 1, что и требуется аксиомой 1.2.
Шаг индукции. Предположим, что при d = n на входе в цикл (после первого выполнения строки 4) на строке 8 имеем равенство d = 0, при этом значение регистра 1 на единицу меньше значения регистра 2, а значит и старого значения регистра r (откуда получаем аксиому 1.2 как следствие леммы 2).
Пусть d = n + 1. На строке 5 имеем неравенство и по аксиоме 2.3 переходим к строке 6. Строки 6–7–4 дают в итоге увеличение на 1 и регистра 1 и регистра 2, после чего d = n на строке 5.
□
Упражнение. Придумайте способ задать команды модели 2 через последовательности инструкций модели 1. Попробуйте доказать корректность полученных конструкций.
Абстрактные регистровые машины позволяют доказывать корректность программ (не произвольных, а соответствующим образом составленных), которые могут быть очень похожи на программы для реальных компьютеров. Показанные выше доказательства довольно подробные. В конечном итоге такие доказательства можно довести до полностью элементарных операций подстановки аксиом и выполнения логических вычислений, что позволяет отчасти автоматизировать процесс доказательства. Последнее может использоваться как непосредственно (доказать, что программа верна), так и как вспомогательный элемент при, например, выполнении оптимизаций оптимизирующим компилятором: компилятор должен доказать, что применяемая замена кода не изменяет результатов вычислений. Корректность самого доказательства, если оно полностью формализовано можно попробовать вычислить непосредственно как истинность булевской формулы.
Формальное доказательство корректности программы называется верификацией (от лат. verus — “истинный, настоящий, верный”).
Арифметики
На основе операций любой из перечисленных выше моделей машин достаточно легко реализовать операции арифметики натуральных чисел: сложение (через повторение инкремента), вычитание (через повторение декремента), сравнение чисел (через декремент или вычитание), умножение (через повторение сложения), деление с остатком (через повторение вычитания), возведение в степень (через повторение умножения), вычисление наибольшего общего делителя (НОД; через вычитание или деление с остатком).
Возможно моделирование произвольных целых чисел как пар натуральных: ∀z ∈ ℤ ∃(n, m) ∈ ℕ2: z = n – m. Это представление не однозначно, но для него можно ввести каноническую форму, удовлетворяющую условию n = 0 ∨ m = 0, которая единственна для каждого целого числа, и которую всегда можно вычислить как (n – min(n, m), m – min(n, m)). Таким образом, если z ≥ 0 представляем его парой (z, 0), иначе — парой (0, –z). Целые числа равны тогда и только тогда, когда их канонические представления поэлементно равны.
Упражнение. Определите операции сложения, вычитания, умножения и деления с остатком для целых чисел, представленных как пары натуральных.
Моделирование рациональных чисел осуществляется по той же схеме как пар целых ∀p ∈ ℚ ∃(n, m) ∈ ℤ2: pm = n — дробей. Канонической формой в этом случае являются несократимые дроби, вычисляемые как (sgn(mn)·|n|/НОД(|n|, |m|), |m|/НОД(|n|, |m|)), где модули и sgn используются, чтобы гарантировать положительность второго элемента (делителя). Рациональные числа равны тогда и только тогда, когда их канонические представления поэлементно равны. Далее можно определить полный набор обычных арифметических операций.
С действительными числами ситуация намного сложнее. Произвольное действительное число невозможно представить в виде конечного описания (цифрового сообщения). Таким образом, оперировать можно только некоторым счётным подмножеством множества действительных чисел — вычислимыми действительными числамиcomputable real numbers. Определяется это подмножество как множество автоматов (программ), позволяющих за конечное число шагов приблизить описываемое действительное число последовательностью рациональных чисел с заданной точностью.
Для способа приближения применяются два эквивалентных определения.
Определение 1. Функция R(n) : ℕ → ℤ представляет некоторое число r ∈ ℝ, если для любого n ∈ ℕ выполняется неравенство R(n)–1 ≤ nr ≤ R(n)+1.
Определение 2 (дедекиндово сечение). Функция D(z) : ℚ → {0, 1} представляет некоторое число r ∈ ℝ, если выполняются следующие условия:
∃zD(z) = 0;
∃zD(z) = 1;
(D(p) = 1) ∧ (D(q) = 0) ⇒ p < q;
D(p) = 1 ⇒ ∃z > pD(z) = 1.
Таким образом, вычислимые действительные числа — это такие действительные числа, для которых можно с любой наперёд заданной точностью за конечное число шагов вычислить рациональное приближение.
Данные определения позволяют определить арифметические действия над вычислимыми действительными числами, однако затруднение представляет сравнение чисел. В частности, определение равенства двух произвольных вычислимых действительных чисел является невычислимой функцией.
При практических вычислениях ограничиваются рациональными числами и рациональными аппроксимациями иррациональных чисел фиксированной точности. Вместо произвольных рациональных чисел обычно используется их подмножество — числа с плавающей запятой.
Моделирование машины Тьюринга
На основе машины-счётчика можно имитировать работу произвольной машины Тьюринга, что делает класс машин-счётчиков эквивалентным машинам Тьюринга, а значит, способными вычислять произвольные вычислимые функции.
Этот факт можно показать, заметив, что бесконечную ленту машины Тьюринга можно моделировать двумя стеками: при движении влево записанное значение вставляется в “правый” стек, вершина левого стека выбрасывается, при движении вправо записанное значение вставляется в “левый” стек, вершина правого стека выбрасывается.
В свою очередь, содержимое стека можно хранить в одном регистре (представить в виде натурального числа). Допустим, размер алфавита машины Тьюринга равен a, пронумеруем буквы алфавита числами от 0 до (a–1). Для вставки буквы в стек домножим регистр на a и прибавим номер буквы. Номер буквы на вершине стека можно получить, взяв остаток от деления на a. Отбросить (вытолкнуть из стека) букву на вершине можно, разделив значение в соответствующем регистре на a.
Для выполнения указанных действий в случае, например, модели 1, дополненной командой безусловного перехода J, достаточно одного дополнительного регистра (обозначим его t). Например, пусть a = 3.
Вставить 1 (именно константу, от её значения зависит число операций INC п.7) в стек s (предположим, что значение t = 0):
JZ s, 7
INC t
INC t
INC t
DEC s
J 1
INC s — вставка единицы, t содержит утроенное s, s было нулём
JZ t, 12
INC s
DEC t
J 8
End: добавили к s значение t, обнулили t
Таким образом, на два стека требуется четыре регистра. Минским (1967) было показано, как такую схему можно свести к машине всего лишь с двумя регистрами. Принцип: четыре исходных регистра (обозначим их значения буквами p, q, s, t) кодируются одним натуральным числом 2p3q5s7t. Этот способ (гёделева нумерация) позволяет закодировать конечный набор произвольных натуральных чисел одним натуральным числом, что часто используется в теоретических конструкциях. Для увеличения на единицу, например, значения p следует удвоить значение этого регистра, а для уменьшения на единицу значения p — поделить на два (аналогично для q — на три, для s — на пять и т.д.). Проверка равенства значения p нулю заключается в проверке остатка от деления на два на неравенство нулю (очевидно, что если p ≠ 0, то 2p3q5s7t делится на 2 без остатка).
Итак, модель 1 с дополнительной командой J может моделировать произвольную машину Тьюринга, используя всего лишь два регистра. Естественно, все другие модели машин-счётчиков, способные моделировать эту модель также способны моделировать и произвольную машину Тьюринга (при этом минимально необходимое число регистров может быть другим).
RAM
Несмотря на то, что машина-счётчик способна моделировать произвольную машину Тьюринга, она является довольно ограниченной моделью компьютера. Главный недостаток заключается в том, что работать с произвольными последовательностями чисел на машине-счётчике неудобно.
Вернёмся к схеме регистровой машины (ниже для удобства иллюстрация приведена повторно).
Схема регистровой машины
Обратим внимание, что машина-счётчик позволяет довольно произвольно изменять регистр PC (командами перехода). Что же мешает изменять регистр RS? Если позволить загружать в RS значение другого регистра, то мы получим возможность косвенного доступаindirect addressing к регистрам (памяти), что позволит одной программе обрабатывать произвольное количество регистров.
Аббревиатура “RAM” расшифровывается как random access machine — “машина произвольного доступа”, что созвучно random access memory — произвольно адресуемой памяти (ОЗУ). RAM разрешает использовать значения регистров для адресации других регистров и предполагает, что память состоит из бесконечного числа регистров, т.е. любому натуральному числу соответствует свой регистр, хранящий произвольное натуральное число.
Для RAM также существует приближённая русскоязычная аббревиатура “РАМ” — “равнодоступная адресная машина”.
Для того, чтобы получить из машины-счётчика RAM, можно добавить операции косвенного копирования:
CPY [a], b — скопировать значение регистра, адрес которого хранится в a, в регистр b.
CPY a, [b] — скопировать значение регистра a в регистр, адрес которого хранится в регистре b.
С точки зрения C++ две этих операции напоминают разыменование указателей.
b = *a; // CPY [a], b
*b = a; // CPY a, [b]
Хотя, если “уважать” ограничения системы типов C++, то корректным аналогом будет обращение к элементам массива по индексам, в качестве которых используются другие элементы того же массива.
unsigned memory[N]; // В RAM N = бесконечность, в реальной программе это, естественно, невозможно.
memory[10] = memory[memory[20]]; // CPY [20], 10
memory[memory[10]] = memory[20]; // CPY 20, [10]
К данной теме примыкает раздел введения “Указатели”.
Модель RAM является основной моделью, применяемой при теоретическом анализе алгоритмов.
RASP
Во введении, начиная с раздела “Последовательность” команды машины нумеровались для того, чтобы можно было задать кодирование программы (в виде последовательности натуральных чисел). Кодирование программы позволяет хранить программу в памяти машины — в тех же регистрах, значения которых используются для хранения данных.
С технической точки зрения для того, чтобы компьютер мог выполнять программу, её необходимо как-то закодировать. Однако сам факт кодирования не означает обязательного размещения программы в общей памяти с данными. Поэтому в модели RAM можно пренебречь способом кодирования. В случае же, если программа хранится в общей памяти, к ней можно обращаться как к любым другим данным. А значит программа может сама себя “читать” и даже изменять себя прямо во время работы (“самомодифицирующийся код”).
RAM, для которой введено кодирование программы и постулируется, что программа хранится в общей памяти, называют RAM with Stored Program (“RAM с хранимой программой”) или сокращённо RASP.
Замечание. RASP может обращаться к произвольному набору регистров даже в том случае, если убрать из набора доступных команд команды косвенного доступа (т.е. использовать в качестве базовой машины не RAM, а машину-счётчик). Дело в том, что номера регистров кодируются и их можно изменять прямо на ходу, выполняя запись в ячейки памяти, в которых хранятся соответствующие команды. Например, пусть по адресу 100 лежит код операции INC, а по адресу 101 записан номер регистра, к которому будет применена команда INC. Какой бы он ни был, из другого места программы можно осуществить запись в 101 произвольного значения, и тогда при выполнении команды INC будет увеличен уже не тот регистр, который изначально был указан в программе, а какой-то другой регистр.
С точки зрения реализации “в железе” машина, хранящая программы прямо в ОЗУ, устроена проще машины, имеющей отдельную память программ и отдельную шину команд, и потому может быть дешевле при условии доступности достаточного объёма ОЗУ.
Схема регистровой машины, хранящей программу в памяти данных
Для обозначения архитектуры компьютерной системы, воплощающей такую схему, используются два термина-синонима: архитектура фон Нейманаvon Neumann architecture и принстонская архитектураPrinceton architecture. Для обозначения архитектуры с разделённой памятью данных и программ используется термин гарвардская архитектураHarvard architecture.
Преимущество разделённых шин и банков памяти заключается в возможности их параллельной работы, т.е. машина гарвардской архитектуры может одновременно считывать следующую команду программы и, например, записывать результат предыдущей команды в память. Современные процессоры, как правило, реализуют “гибридную архитектуру” путём добавления раздельных кэшей инструкций и данных. Таким образом достигается возможность параллельной работы с программой и данными как в машине гарвардской архитектуры, однако за кэшами находится общая память, в которой хранятся и данные и команды как в принстонской архитектуре. Возможность изменять программу “на ходу” сохраняется при использовании гибридной архитектуры, однако попытки делать это с командами, которые вскоре поступят на вход процессора, может вызвать замедление работы из-за необходимости перебрасывать данные между кэшем данных и кэшем инструкций.
Сложность алгоритмов
Одну и ту же задачу можно решать различными способами. В частности, некоторую вычислимую функцию обычно можно реализовать множеством способов даже в рамках одного вида вычислителей. Каждая такая реализация может считаться самостоятельной программой, являющейся воплощением некоторого алгоритма. Алгоритм — это абстрактное (не привязанное к конкретному исполнителю) описание последовательности действий, с помощью которых можно вычислить значение функции для заданного ввода, которое, однако, является достаточно точным и формальным, чтобы можно было “перевести” его в программу для конкретного исполнителя.
Итак, одному алгоритму может соответствовать множество его воплощений в виде конкретных программ, которые можно сравнивать между собой с разных точек зрения: краткости, эффективности использования аппаратных ресурсов, надёжности и т.д. Но на более высоком уровне абстракции также нет единства: одну и ту же функцию вычислять (т.е. решать одну и ту же задачу) можно с помощью разных алгоритмов. Эти алгоритмы опять же можно сравнивать с разных точек зрения: простоты реализации (перевода в программы), количества действий, которые требуется выполнить исполнителю, объёма памяти, занимаемого промежуточными данными, полноты.
Под полнотой здесь понимается степень покрытия различных возможных ситуаций. Строго говоря, формально разная полнота соответствует разным задачам, но на практике часто бывает удобно рассматривать такие задачи как одну. Простой пример: задача решить линейное уравнение. Мы можем заранее предполагать (или точно знать), что уравнение имеет решение — это одна задача. А можем не знать, имеет ли уравнение решение — это другая задача, алгоритм решения которой включает проверку существования решения.
Под сложностью алгоритма понимается зависимость количества операций абстрактного исполнителя (машины Тьюринга, RAM или условного компьютера) от размера исходной задачи. Размер задачи не обязательно прямо пропорционален размеру ввода (описания задачи). Например, задача найти количество простых чисел, меньших N имеет размер N, в то время как для описания ввода достаточно log2N бит.
О-обозначения
Пусть даны две функции f и g, отображающие натуральные числа в натуральные числа (для простоты часто расширяют до действительных чисел, например, указывают логарифм или корень без округления).
Тогда говорят, что f лежит в классе:
ω(g(n)), если ∀C > 0 ∃n0: n > n0 ⇒ Cg(n) < f(n), т.е. функция f(n) растёт асимптотически быстрее, чем Cg(n) для любой положительной константы C;
о(g(n)), если ∀C > 0 ∃n0: n > n0 ⇒ f(n) < Cg(n), т.е. функция f(n) растёт асимптотически медленнее, чем Cg(n) для любой положительной константы C;
Ω(g(n)), если ∃C > 0 ∃n0: n > n0 ⇒ Cg(n) ≤ f(n), т.е. функция f(n) растёт асимптотически не медленнее, чем Cg(n) для некоторой положительной константы C;
O(g(n)), если ∃C > 0 ∃n0: n > n0 ⇒ f(n) ≤ Cg(n), т.е. функция f(n) растёт асимптотически не быстрее, чем Cg(n) для некоторой положительной константы C;
Θ(g(n)), если ∃C1 > 0, ∃C2 > 0 ∃n0: n > n0 ⇒ C1g(n) < f(n) < C2g(n), т.е. скорость роста функций f(n) и g(n) асимптотически одинакова с точностью до положительной константы.
Использование данных обозначений позволяет абстрагироваться от конкретных числовых оценок сложности отдельных “элементарных” операций (TIME, обычно подразумевается по умолчанию) или количества ячеек памяти, занимаемых отдельными значениями базовых “элементарных” типов (SPACE).
Например, линейный поиск в массиве требует O(n) действий, где n — размер массива (размер задачи). В то же время, двоичный поиск в упорядоченном массиве размера n требует O(log2n) действий. Так как логарифмы одного аргумента по разным основаниям отличаются друг от друга множителем-константой, то обычно пишут O(log n) без указания основания. Оба алгоритма поиска не требуют для работы дополнительной памяти, что обозначается через O(1)-SPACE или короче: SPACE(1) — объём требуемой памяти не зависит от размера задачи.
Строго говоря, представление идентификатора элемента множества размера n требует O(log n) знаков (бит), поэтому даже для поиска O(1)-SPACE это упрощение, связанное с тем, что используемые на практике идентификаторы (индексы, адреса) нередко имеют фиксированный размер (32 бита, 64 бита), либо имеют размер, не связанный непосредственно с размером задачи (например, URI).
Если для некоторой задачи лучшие алгоритмы её решения попадают в класс сложности O(g(n)), то говорят, что задача имеет сложностьO(g(n)).
Какой вариант поиска быстрее? Очевидно, что n ∈ ω(log n), таким образом, какова бы ни была корректная реализация двоичного и линейного поисков, всегда найдётся n, начиная с которого двоичный поиск будет работать быстрее. С другой стороны, это n может оказаться не таким уж маленьким. Если, например, приходится постоянно искать значения в массивах из нескольких элементов, то линейный поиск почти наверняка будет работать быстрее двоичного. И это типичная ситуация в мире алгоритмов: асимптотически более медленные алгоритмы обычно проще (в реализации) более быстрых и, как правило, выигрывают в скорости на реальных задачах малого размера. Поэтому их использование может быть оправдано на практике.
Сравнение скорости разных функций времени (1 действие = 1 секунда)
n
log n
n0.5
n log n
n1.5
n2
n3
2n
n!
1с
1с
1с
1с
1с
1с
1с
2с
1с
2с
1с
2с
2с
2с
4с
8с
4с
2с
3с
2с
2с
6с
6с
9с
27с
8с
6с
4с
2с
2с
8с
8с
16с
1мин
16с
24с
5с
3с
3с
15с
15с
25с
2мин
32с
2мин
6с
3с
3с
18с
18с
36с
3.6мин
1мин
12мин
7с
3с
3с
21с
21с
49с
6мин
2мин
1.4ч
8с
3с
3с
24с
24с
1мин
8.5мин
4мин
11ч
9с
4с
3с
36с
27с
1.4мин
12мин
8мин
4д
10с
4с
4с
40с
40с
1.7мин
16.7мин
16мин
41д
30с
5с
6с
2.5мин
3мин
15мин
7.5ч
34г
–
1мин
6с
8с
6мин
8мин
1ч
2.5д
36млрд лет
–
5мин
9с
18с
45мин
1.5ч
25ч
313д
–
–
10мин
10с
25с
1.7ч
4.2ч
4.2д
6.8лет
–
–
30мин
11с
43с
5.5ч
22ч
38д
185лет
–
–
1ч
12с
1мин
12ч
2.5д
150д
1479лет
–
–
2ч
13с
1.4мин
26ч
7д
1.6лет
12тыс лет
–
–
1д
17с
5мин
17д
300д
237лет
20млн лет
–
–
2д
18с
7мин
36д
2.3г
946лет
164млн лет
–
–
Самая быстрорастущая (из приведённых в таблице) функция n! соответствует перебору всех возможных перестановок из n объектов и поначалу растёт вроде бы не так уж и быстро, опережая n3 лишь при n > 5. Однако затем она резко “идёт на взлёт” и, например, 30! ≈ 2.65·1032. Поэтому для малых n (1–4) алгоритмы, перебирающие все перестановки, вполне могут быть пригодны на практике и даже более эффективны, чем другие алгоритмы, но если n велико, то никакой обозримый и физически реалистичный прогресс вычислительной техники не спасёт ситуацию. Например, 30!с на порядки превосходит предполагаемый возраст Вселенной и даже 30!/1018с ≈ 8.4 млн лет. Если же в пространстве перестановок можно организовать двоичный поиск, то получим log n! ∈ O(n log n) — класс, называемый “линеарифмическим” linearithmic (от сложения слов “линейный” и “логарифмический”). В этот класс попадает, в частности, задача сортировки последовательности объектов, для которых задано отношение строгого порядка.
Классы сложности
Итак, пусть задача состоит в вычислении некоторого предиката (надо дать ответ “да” или “нет”). Сложность определяется в операциях машины Тьюринга (TIME) и количестве ячеек, занимаемых на ленте (SPACE).
Формальные языки, понимаемые как произвольные множества фраз, также относят к тем или иным классам сложности: если задача “определить, принадлежит ли строка множеству фраз языка A” принадлежит некоторому классу C, то говорят, что A∈C.
L или LSPACE = SPACE(log N) — класс сложности, в который попадают задачи, для решения которых требуется логарифмическое количество ячеек машины Тьюринга (например, используется фиксированное число указателей или индексов). Примеры: сравнение натуральных чисел, вычисление значения фиксированной булевской формулы для заданных значений переменных.
P или PTIME = ⋃k∈ℕTIME(Nk) — полиномиальная сложность, сюда попадают задачи, время решения которых попадает в O(Nk) для некоторого натурального k. Примеры: проверка натурального числа на простоту, проверка системы линейных неравенств на разрешимость, большинство языков программирования (т.е. задачи проверки синтаксической корректности программ). Можно показать, что LSPACE ⊆ P, так как при решении задачи из класса LSPACE количество всех возможных состояний ленты машины Тьюринга с алфавитом A в случае полного перебора принадлежит O(|A|O(logN)). На данный момент неизвестно, верно ли утверждение “LSPACE = P”.
PSPACE = ⋃k∈ℕSPACE(Nk) — для решения задачи требуется полиномиальный объём памяти. Пример: вычисление булевской формулы, в которой разрешены кванторы существования и всеобщности для переменных. Очевидно, что P ⊆ PSPACE. Неизвестно, верно ли утверждение “P = PSPACE”. С другой стороны, очевидно, что LSPACE ⊂ PSPACE.
EXP или EXPTIME = ⋃k∈ℕTIME(exp(Nk)) — экспоненциальное время работы (в показателе — полином). P ⊂ EXPTIME, PSPACE ⊆ EXPTIME — ситуация аналогична LSPACE ⊆ P. И также неизвестно, верно ли “PSPACE = EXPTIME”.
EXPSPACE = ⋃k∈ℕSPACE(exp(Nk)) — задачи, для решения которых требуется экспоненциальный объём памяти. Верны утверждения: PSPACE ⊂ EXPSPACE, EXPTIME ⊆ EXPSPACE. Неизвестно, верно ли “EXPTIME = EXPSPACE”.
Конечно, можно ввести ещё более трудоёмкие классы, однако с практической точки зрения уже задачи из PSPACE считаются почти нерешаемыми.
В случае, если решение задачи представляет собой нечто более сложное, нежели ответ “да-нет”, вводятся аналогичные классы, к названиям которых добавляется буква F (“функциональный”): например, класс FP содержит арифметические операции над рациональными числами, а также задачи приближённого вычисления многих “математических” функций.
Задачи вычисления отрицания предиката (дополнения) могут порождать собственные классы сложности, обозначаемые с помощью приставки “co-” (от complement — “дополнение”). Для всех вышеперечисленных классов задач вычисления предикатов аналогичные co-классы очевидно совпадают с исходными: L = co-L, P = co-P и т.д., так как достаточно решить “прямую” задачу и вернуть “нет” вместо “да” и “да” вместо “нет” (выполнить булевское отрицание).
Принципиальное (как представляется на данном этапе развития теории алгоритмов) отличие между C и co-C возникает при исследовании классов сложности, вводимых на основе не обычной (описанной в этом разделе) машины Тьюринга (называемой детерминированной), а недетерминированной машины Тьюринга.
Недетерминированная машина Тьюринга (НМТ) отличается от “обычной” (детерминированной) машины Тьюринга (ДМТ) тем, что каждой ситуации (текущие состояние и символ) может отвечать более одного правила. Считается, что НМТ выполняет те правила, которые наискорейшим образом ведут к необходимому результату. НМТ — это абсолютно абстрактный механизм, и неизвестно, возможен ли физический аналог НМТ (с ограниченной памятью). Однако, НМТ вполне можно моделировать на ДМТ: для этого необходимо перебирать все возможные варианты действий, выбирая затем правильный, поэтому множество функций, вычислимых на НМТ совпадает с множеством функций, вычислимых на ДМТ. Впрочем, такое моделирование приводит к тому, что ДМТ выполняет экспоненциально большее количество шагов, чем моделируемая ей НМТ.
Классы сложности для НМТ обозначаются с помощью приставки N: NL, NP, NEXP. Известно, что L ⊆ NL ⊆ P ⊆ NP ⊆ PSPACE ⊆ EXP ⊆ NEXP ⊆ EXPSPACE (однако где-то в этом ряду должны быть строгие включения, так как P ⊂ EXP, NP ⊂ NEXP и L ⊂ PSPACE ⊂ EXPSPACE), а также NL = co-NL, PSPACE = NPSPACE, EXPSPACE = NEXPSPACE (два последних равенства следуют из теоремы Сэвича) Неизвестно, верны ли утверждения: “L = NL”, “NL = P”, “P = NP” (наиболее широко известная открытая теоретическая проблема в области классов сложности — своего рода Великая теорема Ферма), “NP = PSPACE”, “NP = co-NP”, “EXP = NEXP”, “NEXP = co-NEXP”.
В терминах ДМТ задачи разрешимости из N-классов формулируются как задачи проверки сертификата. Так, задача вычисления предиката P(x) принадлежит NP, если существует задача вычисления предиката R(x, y) из P, такого, что для любого x найдётся y (“сертификат”), при котором R(x, y) = P(x). Фактически, сертификат — это и есть решение по существу (см. следующий пример).
Пример. Пусть даны набор чисел размера N и некоторое число a. Задача: существует ли подмножество этого набора чисел такое, что его сумма равна a? Сертификат: само такое подмножество. Для проверки корректности сертификата требуется сравнить сумму всех чисел с a и проверить принадлежность каждого числа исходному набору (что можно сделать, например, линейным поиском). Данная задача относится к классу NP.
Говорят, что задача X (полиномиально) сводима к задаче Y, если существует алгоритм решения X, использующий решение задачи Y полиномиальное по размеру ввода число раз.
Если любая задача из класса C полиномиально сводима к задаче X, то X называют C-труднойhard задачей. Если X, являясь C-трудной, сама принадлежит классу C, то её называют C-полнойcomplete задачей.
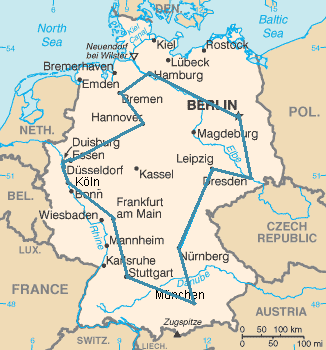
Пример. Пусть дан набор городов и расстояний между ними, а также число d. Требуется узнать, существует ли маршрут, проходящий по каждому городу ровно один раз и при этом имеющий длину не более d (задача коммивояжёра).
Легко показать, что эта задача принадлежащит классу NP. Что более интересно, так это тот факт, что задача также является NP-трудной (т.е. NP-полной). См. список NP-полных задач на англоязычной Википедии.
Задача нахождения маршрута минимальной длины (собственно классическая задача коммивояжёра) принадлежит классу FNP (НМТ может с помощью комбинации решения предыдущей задачи и двоичного поиска найти маршрут минимальной длины за полиномиальное время). На практике подобные задачи требуют экспоненциального времени для нахождения точного решения. С другой стороны, часто доступны методы сравнительно быстрого построения относительно хорошего, но возможно неоптимального решения.